
As Scout continues to grow from year-to-year, we're slowly reaching a point where it's becoming difficult to keep track of the work we've completed and the members that we are constantly gaining and losing. Over the years, we've been trying to fix this problem through email groups, a new Slack workspace for alumni, and an internal newsletter. However, while these all have been proven to be great communication tools, what we really need is an organization tool.
Motivation
The Fall of 2017 introduced to Scout the first Engagement Team: a special task force designed to expand outreach from Scout to its alumni, Northeastern, and the community at large. One of the initiatives they began was a directory that included information about all current members and alumni, resources for designers and developers, and information on how to donate. This prototype was built in Notion.so, and while this was a great tool to show what data we can track, it fell short in a few aspects like scalability and data export.
Coming into the Spring 2018 team, I had hoped to be able to improve on the existing tool we had. Coming from a developer’s perspective, my first thought was that all of this data should exist in an API of sorts. This was backed up by several other internal projects, such as Mentorship and a Scout Wiki, that were being simultaneously developed and relied on the same data. So, after talking with the rest of the team and receiving approval from the higher-ups, I set to work on choosing the best stack for this job.
Choosing a Stack
Since Scout doesn’t operate like a normal studio, in that its members are students who are free to come and go every semester as they please, I couldn’t base my decision on the assumption that myself or another team member was going to continue working past Spring. With that in mind, I set my sights for languages and frameworks that would be easy to pick up. Thankfully, we are in the middle of a boom of widely-available technologies for building our own API and database, giving us a wide range of options to choose from. After weighing the pros and cons of each, we decided on using a language called Python.
Due to Python's widespread use, support, documentation, and all-around ease-of-use, it was the perfect language choice over other alternatives, just barely edging out JavaScript. Adding the Django web framework on top of Python gave us the ability to model objects for all of the data we need to store, including Scout members and projects we've worked on, and easily use those as schemas for our PostgreSQL database tables. Unfortunately, while Django is great for building web apps, it's very limited in scope as to how we can use the data. Enter the Django REST Framework: a library that enabled us to build outward-facing endpoints for the API that could be used by a variety of different internal Scout applications and platforms. All of this then would be served using Gunicorn, a Python WSGI HTTP server, and Caddy as a proxy-server.
Modeling the Data
A few weeks into the semester, I gained a developer in Noah Appleby. Because of my choice to use Python and Django, his onboarding process was smooth and simple, and he was able to start contributing meaningful code within the first few days. We set up a Jira board to keep track of all of our tasks we wanted to complete, and started building the base API scaffold.
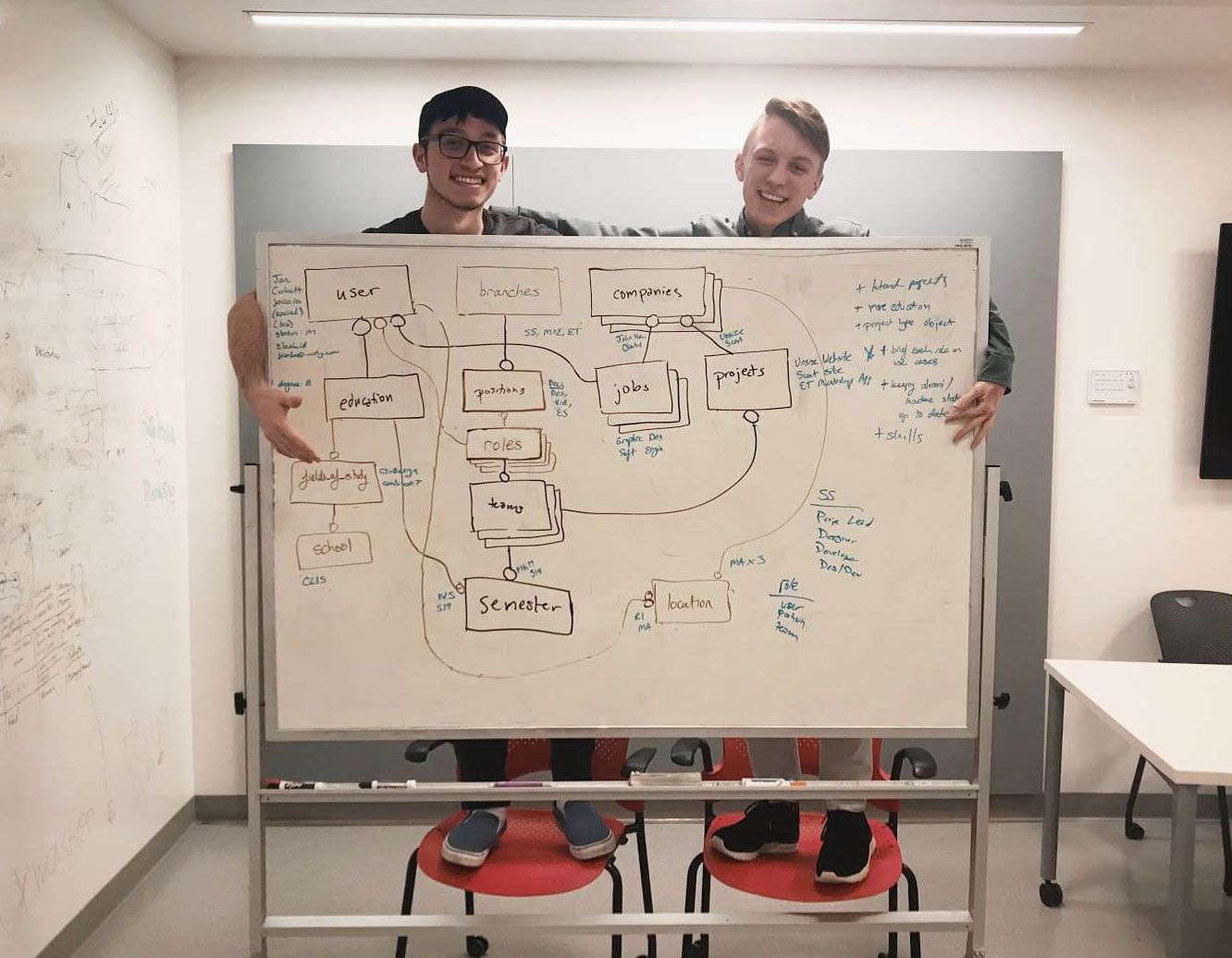
Once the scaffold was created, we started plotting out the different model types we wanted to store in the API. The most obvious of these models was a user, which would store the data for all current, inactive, and alumni members of Scout. Since we wanted to keep track of the positions that these members held in previous years, we added types that modeled the Scout structure; these included semesters, organization “branches,” teams, positions, and roles. We added a project model to use for the work we’ve done and a company model for those we’ve worked with as an organization and those our members have worked for personally. With a few further models mapped out, we had our initial structure for the API and presented it to our team for thoughts and feedback.
Moving On
From that point on until a little past the end of the semester, Noah and I worked hard to finish the API. Although we were never able to get it all done, we prepared a ton of documentation for future developers. Thankfully, our work lived on and continued to be improved upon the following semester. While the API is still not currently live, I hope that the work is one day completed and we’re able to look back on that semester’s work as told by our datasets.